
Microsoft представила Turing Natural Language Generation — самую большую в мире модель с семнадцатью миллиардами параметров. Она создаёт краткие изложения текстовых документов, даёт прямые ответы на вопросы и предлагает слова для завершения предложений. Модель отвечает столь же точно, прямо и свободно, насколько это может сделать человек в разных ситуациях.
Крупномасштабные языковые модели глубокого обучения, например GPT-2 и BERT, с миллиардами параметров, обученных всем доступным в интернете текстам, повысили эффективность выполнения различных задач обработки естественного языка, таких как понимание документов, разговорные агенты и ответы на вопросы.
Большие модели с разнообразными данными предварительной подготовки работают лучше, даже с меньшим количеством обучающих примеров. Эффективнее обучать одну централизованную модель и распределять ее функции между задачами, чем обучать каждую модель отдельно.
Исследователи компании Microsoft, следуя этой тенденции, представили Turing Natural Language Generation (T-NLG) — самую большую в мире модель с 17 миллиардами параметров. Модель превосходит имеющиеся стартовые модели по различным параметрам языкового моделирования.
Модель T-NLG способна генерировать слова для завершения предложений, создавать краткие описания входных документов и давать прямые ответы на вопросы. В отличие от других систем обработки естественного языка, которые основываются на извлечении информации из текстов для создания рефератов или ответов, новая генеративная модель формирует ответы так же точно, прямо и свободно, как это может сделать человек в разных ситуациях.

Обучение T-NLG
Для обучения модели с миллиардами параметров потребуется распараллеливание самой модели или её разделение на части, так как один GPU (даже с 32 ГБ памяти) не способен обработать такое количество параметров.
Исследователи применили для работы аппаратную установку NVIDIA DGX-2, обеспечивающую быстрый обмен данными между GPU, а также нарезку модели на тензоры для распределения её работы по 4 графическим процессорам NVIDIA V100. С помощью библиотеки DeepSpeed и оптимизатора Zero удалось эффективно обучить T-NLG с меньшим количеством GPU.
Исследователи применили аппаратную настройку NVIDIA DGX-2 для ускорения обмена данными между графическими процессорами и тензорную сегментацию, разделив модель на 4 графических процессора NVIDIA V100. С помощью библиотеки DeepSpeed и оптимизатора Zero удалось эффективно обучать T-NLG с меньшим количеством графических процессоров.
Производительность по сравнению со стандартными задачами

Затем сравнили производительность предварительно подготовленного T-NLG с другими мощными трансформаторными языковыми моделями по двум стандартным задачам: точность предсказания следующего слова LAMBADA (выше — лучше) и недоумение Wikitext-103 (ниже — лучше). В обоих случаях T-NLG показал лучшие результаты.
Производительность в ответе на вопрос

Чтобы оценить такие характеристики, как грамматическая точность и достоверность информации, исследователи запросили помощь аннотаторов. Те сравнивали новую модель с моделью LSTM (сходной с CopyNet).
Производительность при активном подведении итогов
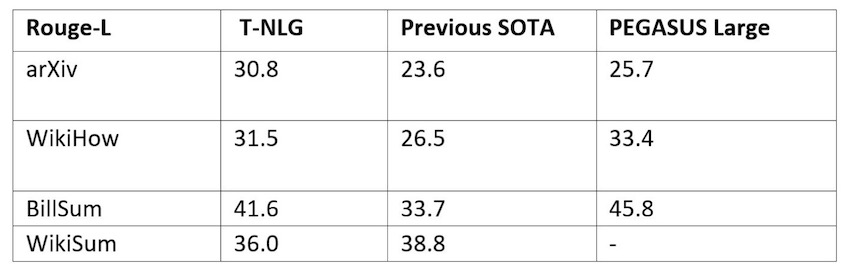
T-NLG способна создавать человекоподобные абстрактные резюме для различных текстовых документов, таких как документы Word, блог-посты, электронные письма, презентации PowerPoint и даже листы Excel. Однако насколько эффективно это по сравнению с другими моделями обработки естественного языка?
Для повышения универсальности модели, способной обобщать все типы текста, исследователи обучили её общедоступным наборам данных обобщения. Затем сравнили модель с другой крупной языковой моделью на основе преобразователя PEGASUS и ее предыдущей версией по баллам ROUGE — метриками для оценки автоматического суммирования при обработке естественного языка.
Применение
Microsoft добилась прорыва в области разговорного искусственного интеллекта. В ближайшие годы интеграция T-NLG в пакет Microsoft Office позволит сэкономить время пользователей: система будет суммировать электронные письма и документы, а также оказывать помощь в написании текстов и отвечать на вопросы по их содержанию.
Данные позволяют создать более точных и быстрых цифровых помощников и чат-ботов, что поможет компаниям управлять продажами и отношениями с клиентами.