Этот материал можно услышать в аудиоформате.
Машинное обучение чаще всего связывают с распознаванием и созданием изображений. Системы искусственного интеллекта, например, DALL-E или Imagen, удивляют способностью генерировать картинки, которые трудно отличить от иллюстраций художников или фотографий. Лица, созданные нейронными сетями, становятся все более реалистичными и даже вызывают у людей больше доверия, чем фотографии настоящих людей.

На экране монитора генеративные сети оживляют умерших знаменитостей. На выставке, посвященной Сальвадору Дали, посетителей приветствует сам Дали, произносящий вдохновенную речь своим голосом с экспрессией и мимикой, характерными для него. Дипфейк создает полную иллюзию живого художника, словно видео было записано незадолго до события.

В работе с текстом нейросети не уступают моделям, обученным на изображениях. Онлайн-перевод уже занимает секунды, но большие языковые модели пошли дальше: читают текст и отвечают на вопросы по нему, руководствуясь логикой и здравым смыслом. Юмор тоже им понятен. Количество параметров таких сетей постоянно увеличивается.
Новое ПО PaLM содержит 540 миллиардов параметров, в три раза больше, чем у GPT-3. В Китае на экзафлопсеном суперкомпьютере создаётся система BaGuaLu для обучения модели с 14,5 триллионами параметров. Разработчики утверждают, что BaGuaLu потенциально сможет обучать модели с 174 триллионами параметров, что превышает количество синапсов в человеческом мозге.
Несмотря на то что прорывы в работе с изображениями и текстами последних лет получили большую известность, достижения машинного обучения простираются далеко за их пределы. Способность нейронных сетей учиться и анализировать большие объемы данных уже широко используется во многих областях. Рассмотрим эти менее популярные, но столь же важные применения МО более подробно.
Как мы поймем, из чего все сделано (физика)
Десять лет алгоритмы машинного обучения активно применяются в исследованиях на Большом адронном коллайдере. Машинное обучение используется для моделирования и калибровки детекторов, сбора данных, распознавания образов и идентификации частиц. Оно становится распространенным инструментом во всех сферах физических исследований: от разработки и оптимизации экспериментов до сбора и анализа данных, численного моделирования и даже разработки теории.
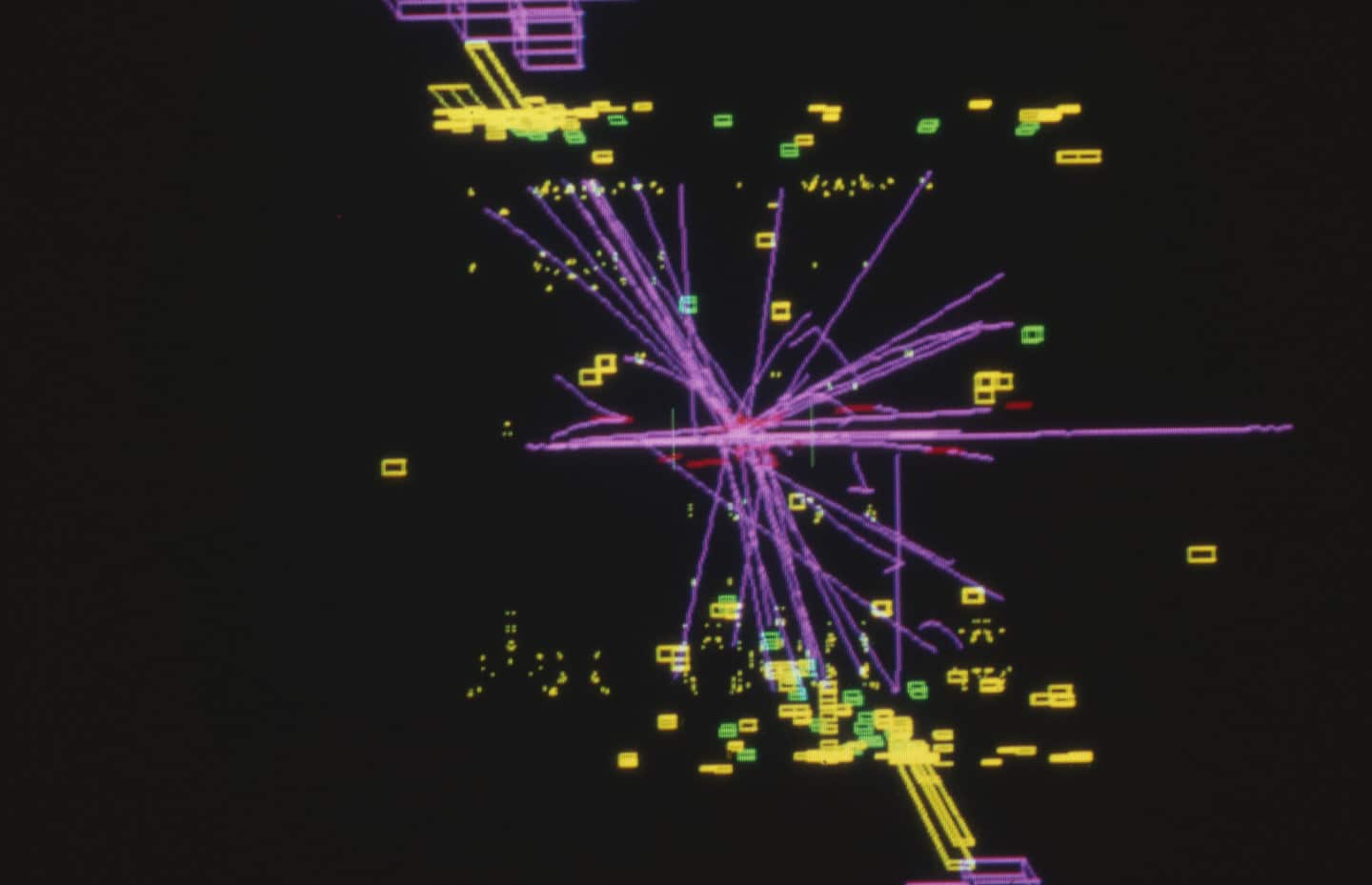
Ученые обычно исследуют редкие отклонения от Стандартной модели. Часто ни одно из них не кажется необычным само по себе — только множество примеров позволяет получить статистическое подтверждение открытия. Таким образом, появляется большой поток сложных экспериментальных данных, а физики с помощью машинного обучения ищут закономерности, тенденции и аномалии в этом запутанном ландшафте для получения важных выводов.
В теоретической физике математические концепции и модели применяют для создания синтетических данных — набора результатов моделирования. Системы машинного обучения, обученные таким данными, могут делать прогнозы для моделей стабильности планетных систем и генерировать гипотезы в теории узлов и теории представлений.
Студенты магистратуры университета «МИСИС» « Полупроводниковые преобразователи энергииУчаствуют в экспериментах, которые выполняется в рамках коллаборации LHCb (ЦЕРН) для исследования фундаментальных свойств новых частиц легкой темной материи.
Прикладные физики научили нейронную сеть управлять настоящим термоядерным реактором. Внутри него мощные магнитные поля удерживают раскаленную плазму. Магниты не дают ей коснуться стенок реактора, и задача состоит в том, чтобы удержать плазму достаточно долго для извлечения энергии. Удержание плазмы требует постоянного контроля магнитного поля, поэтому ученые обучили нейронную сеть на симуляции.
После того как удалось управлять формой плазмы в виртуальном реакторе, её перевели на настоящий экспериментальный токамак в Лозанне. Управление реактором длилось всего две секунды, но в физике высоких энергий это время огромно. Алгоритм выполнял 90 измерений, описывающих форму и положение плазмы, и регулировал напряжение в 19 магнитах 10 тысяч раз в секунду.
Как понять взаимосвязь явлений в химии?
Многие существующие теории химии построены на ограниченном количестве данных и могут быть предвзятыми. Машинное обучение позволяет вернуться к началу и создавать новые правила на основе обширных наборов информации. Цель — изучить статистическую связь между химической структурой и потенциальной энергией, не прибегая к общепринятым представлениям о связях или знаниям о взаимодействиях.
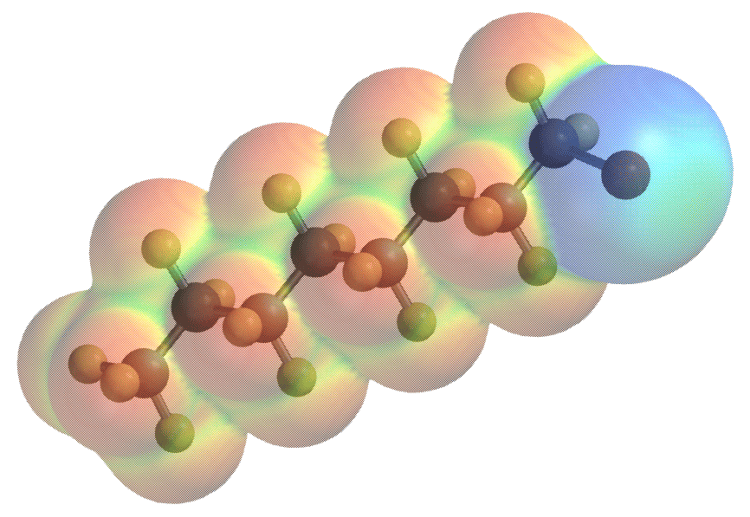
Для расчета движения молекул нужно знать силы, воздействующие на каждый атом в каждом моменте моделирования. Точный способ выяснить эти силы — это решение уравнения Шрёдингера, которое описывает законы физики большинства химических явлений.
Но его аналитическое решение доступно только для простых систем из двух тел, например, атома водорода. Для больших химических структур уравнение решают приблизительно, но даже это требует сложных и длительных вычислений.
Машинное обучение существенно сокращает время и ресурсы, не требуя решения уравнений. За счет этого возможность стало всё популярнее у химиков в последние годы. Методы МО позволяют исследовать химическое пространство и предсказывать свойства соединений с большой точностью.
Методы МО привели к новым химическим открытиям в давно изученных системах. Выяснилось, что даже маленькие молекулы демонстрируют нетривиальные электронные эффекты, которые влияют на их поведение и помогают лучше понять экспериментальные данные. Благодаря методам МО множество других неизвестных химических эффектов ещё ждёт своего открытия.
Из чего мы все построим (дизайн материалов)
Тенденции устойчивого развития и надвигающейся экономической модели побуждают к поиску новых материалов с заранее предсказуемыми характеристиками. Достигнуты все очевидные успехи в материаловедении, традиционные методы не справляются с растущей сложностью конструкций необходимых нам материалов. Сложность проектирования этих материалов заключается в огромном пространстве возможных вариантов реализации, которое часто недоступно для прямого вычисления, а физическая интуиция оказывается неэффективной.
Машинное обучение всё чаще используется для проектирования новых материалов благодаря прогнозированию свойств, генерации структур с нуля и открытию принципов, недоступных человеческому разуму. С помощью машинного обучения можно обнаруживать закономерности в данных, предсказывать свойства не существующих ещё материалов и оптимизировать их характеристики.
Машинное обучение применяется для проектирования различных композитов, полимеров, катализаторов и энергетических материалов, таких как батареи, электролиты, электроды, фотогальваника.
В Университете «МИСИС» обучают специалистов в области искусственного интеллекта, дата-サイенс, big data и робототехники. Партнерами магистерских программ является Сбер – российский лидер в сфере информационных технологий, предоставляющий студентам свою инфраструктуру для исследований.
Машинное обучение используется для синтеза наночастиц из полупроводников, металлов, углерода и полимеров.
Такие частицы применяются во многих областях: химическом зондировании, диагностике в медицине, катализе, термоэлектрике, фотовольтаике и фармацевтике. Синтез этих частиц с точно контролируемыми свойствами осуществляется с помощью поиска оптимальных сочетаний параметров, которое упрощается машинным обучением.
Синтетические полимеры обладают бесчисленными комбинациями мономеров, что приводит к разнообразным сочетаниям структуры и функции (например, ионная проводимость, эффективность фотопреобразования, реакция памяти формы и самовосстановление). Для проектировщика материалов это означает высокую сложность: такую комбинаторную структуру нельзя вычислить или вывести из общих принципов. Машинное обучение с его способностью обнаруживать скрытые связи и корреляции в сложных ландшафтах структуры и функции помогает преодолеть эту трудность, генерируя структуры на основе заданных функций, подобно тому, как нейронные сети создают изображения из текста.
Каким образом мы построим все, что нам нужно (инженерия)
В разработке сложных устройств с большим количеством параметров и данных машинное обучение может быть полезно по тем же причинам, что и в предыдущей главе. Например, Боинг 787 состоит из 2,3 миллиона деталей и во время испытаний получает данные от 200 тысяч мультимодальных датчиков. В процессе эксплуатации самолет генерирует множество данных, которые собираются и обрабатываются с помощью 18 миллионов строк кода, лишь для систем авионики и управления полетом.

Проектирование самолетов — это многоэтапная задача по достижению наилучших характеристик при наличии ограничений, таких как дальность полета, запас топлива, стоимость производства и ожидаемый доход. Использование данных для анализа взаимосвязи параметров создает основу для успешного модернизации. Машинное обучение в сочетании с технологией цифрового двойника позволяет предсказывать и оптимизировать работу реальных самолетов.
Инженеры могут столкнуться с ещё одной проблемой при работе с устройствами большой степени свободы — моделированием их поведения. Податливость и вязкоупругость материала приводят к сложному и непредсказуемому поведению из-за нелинейности системы: связь между входом и выходом робота не может быть представлена простой линейной зависимостью. Машинное обучение эффективно именно в нелинейных задачах, поэтому его применяют в «мягкой» робототехнике для калибровки мягких датчиков, позиционирования приводов, захвата и планирования движения роботов.
В 2021 году студенты Университета «МИСИС» создали прогностическую модель для газораспределительной сети Москвы. Модель, основываясь на положении клапанов, предсказывает параметры давления и потребления газа как промышленными предприятиями, так и частными лицами. Это позволит управлять сложной системой газоснабжения столицы, сделав ее более энергоэффективной и безопасной.
Машинное обучение используется для настройки квантовых устройств, то есть для поиска набора параметров, которые кодируют и оптимизируют кубит. Так, компания DeepMind преодолела барьер сложности на полупроводниковых устройствах с квантовыми точками при помощи методов машинного обучения. Для настройки квантовых устройств в режиме реального времени методы машинного обучения применяют и в других реализациях кубитов: таких как сверхпроводящие кубиты, или центры азотных вакансий в алмазе, или ионные ловушки.
А теперь поговорим за жизнь (биология)
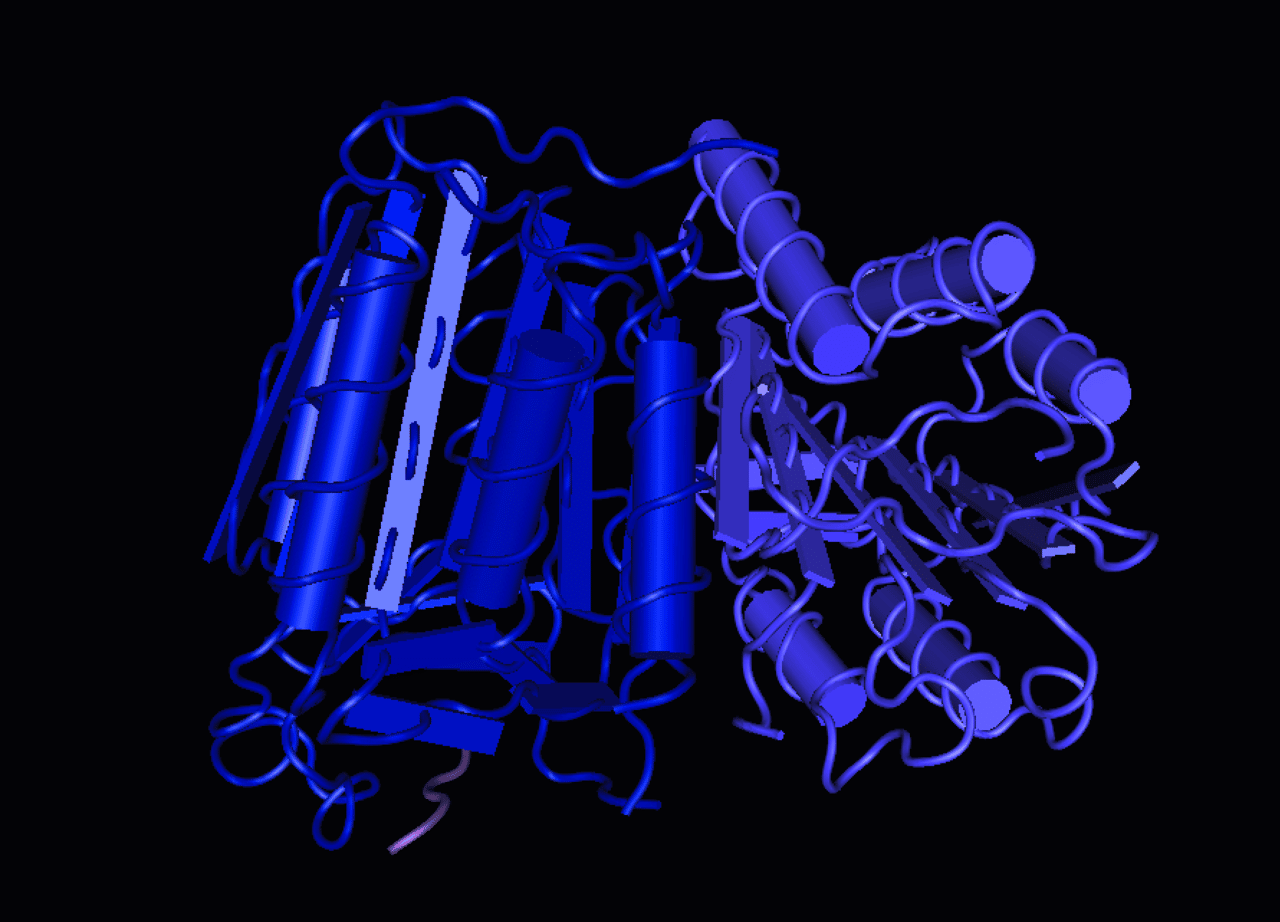
В биологии также возникли трудности из-за огромного пространства потенциальных структур важных молекул, таких как ДНК, РНК и белки. Трудно определить форму белка по составу и порядку аминокислот. Структура белка определяет его свойства, поэтому это всегда было важно для биологов. Машинное обучение помогло решить эту проблему.
В 2015 году AlphaGo, разработка компании DeepMind, одержала победы над европейским чемпионом по игре в го и миром-чемпионом. Программа применяла глубокие нейронные сети и сначала обучалась на партиях, сыгранных людьми, а затем её версия играла против себя, повышая свой уровень без помощи игр людей.
Го обладает огромным потенциалом комбинаций, что делает её похожей на проблему свертывания белка. Разработчики AlphaGo решили оценить возможности программы в биологии, обучив AlphaFold на данных известных структур белков. Задача AlphaFold заключалась в предсказании наиболее вероятных структур белков, о которых известно только то, что они сворачиваются.
Программа показала высокую точность в прогнозировании структуры белков, не рассчитывая при этом кинетику или стабильность фолдинга. AlphaFold набрала 90 баллов из 100 в ежегодном конкурсе «Крупномасштабный эксперимент по предсказанию структуры белка» (CASP), после чего многие специалисты посчитали задачу предсказания структуры белка полностью решенной.
AlphaFold показал возможности машинного обучения в решении задачи, которая сложна для других методов. Сердцем AlphaFold является нейронная сеть, обученная на множестве структур для предсказания расстояний между атомами. AlphaFold может быть полезной технологией, например при проектировании лекарств, где зачастую отправной точкой является знание структуры белка.
Мы исцелим всех от большинства недугов.
Разработка лекарства от открытия до выхода на рынок обходится в среднем более чем в один миллиард долларов США и может занять 12 лет и более. Усилия уходят на поиск и разработку действующего вещества, а также на подтверждение его эффективности у людей. Дело в том, что организм невероятно сложен, клетки, биомолекулы, гены и другие вещества связаны между собой. Эта сложность не поддается прямому анализу, но, как выяснилось, может быть преодолена с помощью машинного обучения.

В медицине быстро растёт доступность клинических данных различных уровней биологической сложности: от мультиомики и молекулярных путей до визуализационных данных, электронных медицинских карт и информации с имплантируемых устройств и носимых датчиков. Такая информация может быть использована в машинном обучении для получения интересных результатов.
В полногеномных ассоциативных исследованиях (GWAS) уже применяется машинное обучение для связи генетической информации с данными о здоровье. Следующим этапом станет интеграция эпигенетических, протеомических, метаболических и других данных. Это потребует больших ресурсов, но может дать высокие результаты. Машинное обучение способно обрабатывать разнородные и сложные данные, выявляя скрытые взаимосвязи. Например, с помощью машинного обучения уже возможно предсказать эффективность лечения антидепрессантами или рака на основе геномики и клинических данных. Это позволит пациентам избежать ненужных, часто сложных и дорогих процедур.
В 2020 году сотрудничество учёных Университета «МИСИС», Института русского языка имени В. В. Виноградова РАН и НИУ ВШЭ запустило масштабный проект по созданию с помощью искусственного интеллекта и машинного обучения уникальной базы древнеславянских рукописных текстов — корпуса.
Машинное обучение всё чаще используют для отбора лекарств, прогнозирования их свойств и поиска терапевтических мишеней. Есть надежда, что оно поможет пролить свет на природу и развитие сложных заболеваний, таких как рак или болезнь Альцгеймера. Например, анализ более 11 тысяч опухолей 33 типов рака существенно улучшил понимание того, как рак мутирует из исходных клеток и какие факторы влияют на развитие опухоли. Глубокое понимание рака жизненно необходимо: многие лекарства разрабатывают на основе экспериментально подтвержденной гипотезы, которая может объяснить возможный механизм канцерогенеза, но игнорирует другие факты о болезни.
Врачам поможет искусственный интеллект принимать решения и повысить качество диагностики и прогнозов, обнаруживая новые связи. Главная задача — сделать модели глубокого обучения понятными, для чего потребуется дополнительная работа.
Что у нас может не получиться?
Нейронная сеть принимает данные и выдаёт результат. О том, насколько точно отражает она действительность, судить нельзя без заранее известного правильного ответа. Сам процесс «мышления» сети скрыт от нас (даже слово «мышление» здесь стоит в кавычках) — поэтому его называют «черным ящиком». В медицине и сфере безопасности это серьёзная проблема, требующая решения: необходимо быть уверенными, что сеть не заблудилась, а нашла реальную закономерность, а не ошибку.
Другой проблемой может быть приблизительность ответов в машинном обучении. Там, где допустимы неидеальные ответы и риски малы, например при создании изображений или переводе текстов, методы машинного обучения показывают свою эффективность, и мы можем им доверять. В диагностике или управлении автомобилем такой риск неприемлем, поэтому глубокие нейронные сети еще не произвели революцию в этих областях.
Нейронные сети сильно зависят от качества данных для обучения. Низкое качество входных данных неизбежно приводит к неточностям в результатах.
Сбор чистых и качественных данных в реальном мире может быть трудным или дорогостоящим. Даже при наличии чистых данных, нейросеть может сформировать предвзятость, поскольку обучающая выборка может содержать незаметные предубеждения и искажения.
Обученные нейросети эффективно распознают закономерности и связывают данные, однако эти связи носят ассоциативный характер и не всегда отражают причинно-следственную зависимость. В науке, где поиск причин – приоритетная задача, это свойство машинного обучения может быть недостатком.
Необходимо помнить о том, что глубокое обучение потребляет много ресурсов. Достижение хороших результатов требует больших объемов данных для обучения, а крупные модели (например, языковые) нуждаются в мощных вычислительных ресурсах и, в конечном счете, затратах энергии (и ресурсов).
Сети глубокого обучения могут ошибаться, иногда до абсурда. Это свидетельствует о том, что они не понимают мир, а лишь реагируют на статистические закономерности.
Несмотря на это, умение распознавать паттерны в данных очень полезно и позволяет решать определенные задачи. В будущем специалистам предстоит раскрыть полный потенциал машинного обучения.
Если данный текст заинтересовал вас и вы желаете испытать свои силы в этой сфере, предлагаем рассмотреть магистратуру « Искусственный интеллект и машинное обучение» в Университете «МИСИС».