Швейцарский плазменный центр и компания DeepMind создали новый способ управления плазмой в токамаке при помощи магнитных полей.
Алгоритм глубокого обучения с подкреплением, разработанный DeepMind, существенно ускоряет настройку токамака для получения заранее заданных конфигураций плазмы с высокой точностью.

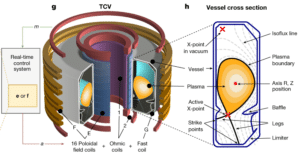
Токамак — это установка тороидальной формы с магнитными катушками, предназначенная для проведения управляемого термоядерного синтеза, аналогичного процессам в звездах.
В токамаках создаются сильные магнитные поля и вакуум для удержания плазмы высокой температуры и защиты стенок от расплавления. Теоретически полученная энергия может быть использована для производства электроэнергии.
Швейцарский плазменный центр Федеральной политехнической школы Лозанны имеет многолетний опыт в физике плазмы и её управлении. SPC — один из немногих исследовательских центров мира с действующим токамаком, имеющий возможность создавать разные конфигурации плазмы, управляемые положением магнитных катушек. Поэтому его называют токамаком переменной конфигурации (TCV).
Наличие определённой формы и положения плазмы в токамаке обуславливает её устойчивость и производительность реактора, то есть количество генерируемой энергии. Перед проведением экспериментов на установке исследователи из SPC сначала проверяют конфигурации систем управления на симуляторе.
Основанный на многолетних исследованиях и регулярно обновляемый, наш симулятор был разработан Федерико Феличи. Federico Felici«— Даже в таком случае, для определения правильного значения каждой переменной в системе управления всё ещё требуются продолжительные вычисления. Именно здесь начинается наше совместное исследовательское сотрудничество с DeepMind».
DeepMind — британская компания, занимающаяся научными открытиями в области искусственного интеллекта. Google приобрела компанию в 2014 году. DeepMind стремится решать проблемы ИИ для развития науки и человечества. Эксперты компании разработали алгоритм глубокого обучения с подкреплением, который может создавать и поддерживать определенные конфигурации плазмы. Его обучили на симуляторе SPC.
Сначала алгоритм опробовал разные стратегии управления плазмой в симуляции, накапливая опыт. Обучение шло двунаправленно: сначала задавались параметры для установки, по которым генерировалась плазма на симуляторе, а алгоритм анализировал её форму; затем по форме плазмы алгоритм выявлял правильные настройки.
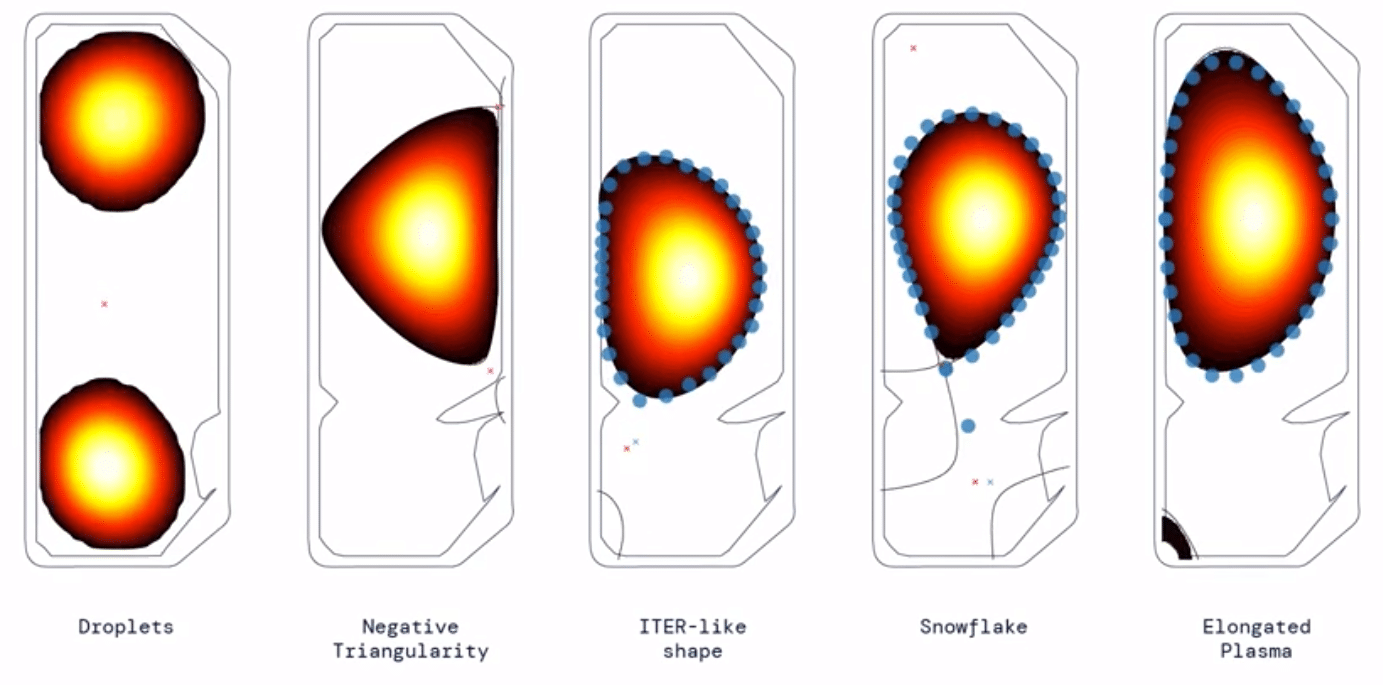
Обученная по алгоритму DRL система создавала и поддерживала разнообразные формы плазмы и сложные структуры в симуляторе, включая ситуацию с двумя разделенными фрагментами плазмы в реакторе.
Исследователи испытали новую систему на токамаке, чтобы оценить её работу в условиях реального эксперимента. Созданные алгоритмом DRL и предсказанные симулятором SPC конфигурации удалось получить на установке. Новый подход к управлению магнитными катушками токамака ускоряет создание необходимых конфигураций плазмы и обеспечивает точное отслеживание местоположения, тока и формы для этих конфигураций.
Мартин Ридмиллер (Martin RiedmillerРуководитель группы управления в DeepMind и соавтор исследования подчеркнул: «Наша команда стремится изучать системы искусственного интеллекта нового поколения — контроллеры с обратной связью, способные обучаться на сложных динамических средах без предварительной информации. Управление термоядерной плазмой в реальных установках предоставляет потрясающие, хотя и невероятно сложные возможности».
Статья с результатами исследования опубликована в журнале Nature.