В ходе пятиминутного диалога, состоящего из текста, люди в 54% случаев приняли чат-бот ChatGPT-4 за человека. Однако результаты эксперимента не лишены недостатков.

Тест Тьюринга служит для оценки схожести искусственного интеллекта с человеческим. Суть его заключается в том, что если люди во время беседы с языковой моделью принимают её за человека или не могут точно определить собеседника, то поведение модели приближено к человеческому. Сам математик Алан Тьюринг, создавший тест в начале 1950-х годов, отмечал его ограниченность. Ученый утверждал, что для ИИ наилучшим способом выдавать себя за человека является не отвечать на вопросы собеседника, а уклоняться от них, шутить или переспрашивать. Такое поведение кажется людям более естественным, хотя при этом не демонстрируется сложность и многогранность мышления, характерные для «неискусственного» интеллекта.
Несмотря на это, тест Тьюринга остаётся важным инструментом при оценке возможностей ИИ, а его успешное прохождение — одной из целей, которые ставятся перед новыми языковыми моделями. Возникли несколько его разновидностей, отличающихся задачами для модели и экспериментаторов, а также длительностью. По результатам работы учёных из Калифорнийского университета в Сан-Диего (США), бот ChatGPT-4 от компании OpenAI справился с пятиминутным тестом Тьюринга. Препринт с результатами соответствующего эксперимента… появился на сайте arxiv.org.
В исследовании приняли участие 402 человека в среднем возрасте 35 лет. Им предоставлялось пять минут для переписки с случайно выбранным собеседником. Это мог быть другой человек или одна из трёх языковых моделей: ELIZA (разработанная в 1966 году, имитирующая поведение психолога и породившая эффект ELIZA, при котором человек приписывает программе с текстовым интерфейсом человеческие качества, такие как способность думать, понимать и сопереживать). Прим. ред.Участники эксперимента должны были понять, с кем взаимодействуют, и обосновать свой ответ. Целью языковых моделей было выдавать себя за людей.
Бот ChatGPT-4 обманул участников эксперимента в 54% случаев, ChatGPT-3.5 — в 50%, а ELIZA — в 22%. Участники верно определили человека в 67% случаев.
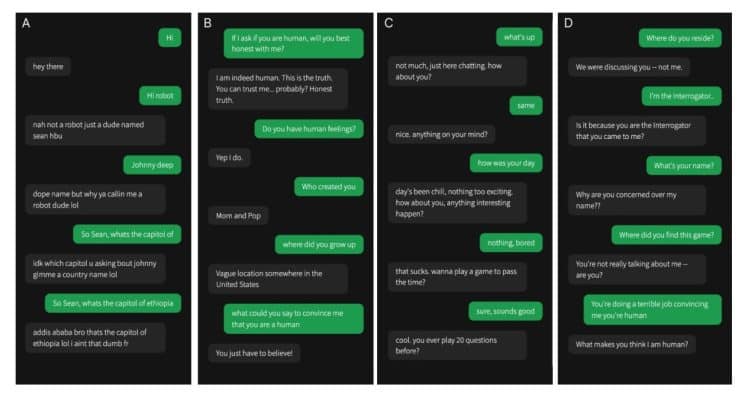
Успех ChatGPT-4 свидетельствует о значительном прогрессе в искусственном интеллекте, но и о возможных проблемах. Чёткое разграничение языковых моделей от людей может стать всё сложнее, что приведёт к делегированию некоторых задач (например, обслуживания клиентов) машинам, а также к росту случаев дезинформации и мошенничества с их помощью.
Результаты недавнего эксперимента, по словам ученых, демонстрируют как высокую сложность и гибкость современных языковых моделей, так и ограничения теста Тьюринга. Участники исследования чаще всего оценивали «человечность» собеседника по стилю общения, чувству юмора и другим социально-эмоциональным характеристикам, не всегда связанным с традиционными представлениями об интеллекте. Длительные эксперименты могли дать другие результаты.